-
정보처리기사 필기 5과목 - 정보시스템 구축관리 (빈출 요점 정리)시험 요점정리 (꽃길)/정보처리기사 2021. 7. 31. 15:07
정보처리기사 필기 빈출 개념과 기출문제를 정리하였습니다.
공부할 시간이 부족할 경우 아래의 개념을 먼저 학습해보시고, 기출문제들을 최소 3회차를 풀어볼 것을 권장합니다.
(기출문제: https://www.comcbt.com/xe/iz)
(전체 목차 및 다른 과목 링크: https://computer-choco.tistory.com/437)
정보처리기사20200926(해설집).hwp0.11MB정보처리기사20200822(해설집).hwp0.13MB정보처리기사20200606(해설집).hwp0.10MB(기출문제 출처는 위의 링크와 같습니다 - comcbt.com)
정보처리기사 필기 5과목 - 정보시스템 구축관리 빈출 개념 & 기출 문제
1. 고전적 생명 주기 모형
2. 나선형 모형
3. 비용 산정 기법
4. COCOMO 모델
5. CMM 모델
6. 소프트웨어 개발 프레임워크
7. RIP vs. OSPF
8. 암호화 알고리즘
9. 정보보안 3대 요소
10. 공격기법
보너스. CBD
보너스. 신기술 용어
1. 고전적 생명 주기 모형 ★★★
교재 단원: 소프트웨어 개발 방법론 활용
정보처리기사 필기 (2020.06.06 ~ 2020.09.22) 의 3번의 시험 중 출제율 100%에 해당하는 개념입니다.
소프트웨어 생명주기 모형 중 애자일 기법은 1과목에서 많이 출제가 되고, 폭포수 모형 (고전적 생명주기 모형) 과 나선형 모델은 5과목에서 많이 출제가 됩니다. 소프트웨어 생명주기 모형은 소프트웨어 개발을 하기 위해 정의, 운용, 유지보수하는 과정들을 각 단계별로 나눈 것입니다. (만들고 ~ 문제가 생기면 수정하는 일련의 과정들인 것입니다)
소프트웨어 생명주기 모형
(1) 폭포수 모형
(2) 프로토타입 모형
(3) 나선형 모형
(4) 애자일 모형[참고] 소프트웨어 생명주기 모형 참고: https://liveyourit.tistory.com/197 혹은 https://ithotplace.tistory.com/3
고전적 생명주기 모형은 폭포수 모형 (Waterfall Model) 이라고 합니다. 폭포에서 한번 떨어진 물을 거슬러 올라갈 수 없듯이 소프트웨어 개발도 이전 단계로 돌아갈 수 없다는 전제 하에 각 단계를 확실히 매듭짓고, 그 결과를 철저하게 검토하여 승인하는 과정을 거친 후에 다음 단계로 진행하는 개발 방법론입니다.
타당성 검토 -> 계획 -> 요구분석 -> 설계 -> 구현 - > 검사 -> 유지보수 순으로 진행이 됩니다. (굉장히 엄격한 순차적인 단계가 있어보입니다.)
어떤 느낌인지 감이 오시나요? 바로 문제를 풀어보겠습니다.
83. 다음 설명에 해당하는 생명주기 모형으로 가장 옳은 것은?
가장 오래된 모형으로 많은 적용 사례가 있지만 요구사항의 변경이 어려우며, 각 단계의 결과가 확인되어야지만 다음 단계로 넘어간다. 선형 순차적 모형으로 고전적 생명 주기 모형이라고도 한다.
(1) 패키지 모형
(2) 코코모 모형
(3) 폭포수 모형
(4) 관계형 모델
(2020.09.26 정보처리기사 필기 기출문제 - 출처: 전자문제집 CBT)가장 오래된 고전적인 모형 혹은 고전적 생명 주기 모형이라는 것에서 바로 3번을 고르셨어도 됩니다. 또는 각 단계의 결과를 확인해야만 다음 단계로 넘어간다는 것 또한 폭포수 모형의 특징입니다.
많이 출제된 문제이기 때문에 다른 형태의 문제도 한 번 풀어보겠습니다.
98. 폭포수 모형의 특징으로 거리가 먼 것은?
(1) 개발 중 발생한 요구사항을 쉽게 반영할 수 있다.
(2) 순차적인 접근방법을 이용한다.
(3) 단계적 정의와 산출물이 명확하다.
(4) 모형의 적용 경험과 성공사례가 많다.
(2020.06.06 정보처리기사 필기 기출문제 - 출처: 전자문제집 CBT)답은 1번입니다. 2번의 순차적인 것도 맞고, 3번 단계별 산출물이 명확한 것도 많고, 4번 가장 오래된 모형이니 적용 경험도 많습니다. 그러나 1번은 개발 중 요구사항이 발생한다고 해서 이전 단계로 거슬러 올라가서 바꿀 수는 없습니다.
2. 나선형 모형 ★★★
교재 단원: 소프트웨어 개발 방법론 활용
정보처리기사 필기 (2020.06.06 ~ 2020.09.22) 의 3번의 시험 중 출제율 100%에 해당하는 개념입니다.
소프트웨어 생명주기 모형 중 프로토타입 모형은 샘플 (프로토타입) 을 만들어서 최종 결과물을 예측합니다. 고객의 요구사항을 받아서 그 샘플을 바꿔가면서 최종 구현 때까지 반복하는 것입니다.
소프트웨어 생명주기 모형
(1) 폭포수 모형
(2) 프로토타입 모형
(3) 나선형 모형
(4) 애자일 모형[참고] 소프트웨어 생명주기 모형 참고: https://liveyourit.tistory.com/197 혹은 https://ithotplace.tistory.com/3
위에서 말씀드린 폭포수 모형과 방금 말씀드린 프로토타입 모형을 합한 나선형 모형이 있습니다.
나선형 모형 (Spiral Model) 은 나선을 따라 돌듯이 (아래 그림을 보면 소라 껍데기처럼 둥글게 도는 나선형 모양을 보실 수 있습니다) 여러 번의 소프트웨어 개발 과정을 거쳐 점진적으로 완벽한 최종 소프트웨어를 개발하는 것입니다. 성과를 보면서 점진적으로 진행하는데 (폭포수 모형의 장점), 고객 평가를 받아 (프로토타입 모형의 장점) 다시 과정을 반복합니다. 기존 모델들과 다른 점은 '위험 분석' 단계가 추가되었습니다. 프로젝트시 발생하는 위험을 관리하고 최소화하려는 목적이 있습니다.
계획 수립 -> 위험 분석 -> 개발 -> 고객 평가 순으로 진행이 됩니다.

[그림 출처] https://itwiki.kr/w/%EB%82%98%EC%84%A0%ED%98%95_%EB%AA%A8%EB%8D%B8
문제를 풀어보겠습니다.
91. 프로토타입을 지속적으로 발전시켜 최종 소프트웨어 개발까지 이르는 개발방법으로 위험관리가 중심인 소프트웨어 생명주기 모형은?
(1) 나선형 모형
(2) 델파이 모형
(3) 폭포수 모형
(4) 기능점수 모형
(2020.06.06 정보처리기사 필기 기출문제 - 출처: 전자문제집 CBT)답은 1번입니다. 프로토타입이라는 단어가 나오면 보기에서 프로토타입 모형 혹은 나선형 모형을 찾아주시면 됩니다. 다른 형태의 문제도 풀어보겠습니다.
95. 소프트웨어 개발 모델 중 나선형 모델의 4가지 주요 활동이 순서대로 나열된 것은?
(A) 계획 수립
(B) 고객 평가
(C) 개발 및 검증
(D) 위험 분석
(1) A-B-D-C 순으로 반복
(2) A-D-C-B 순으로 반복
(3) A-B-C-D 순으로 반복
(4) A-C-B-D 순으로 반복
(2020.08.22 정보처리기사 필기 기출문제 - 출처: 전자문제집 CBT)답은 계획 수립 - 위험 분석 - 개발 - 고객 평가 순으로 진행되는 2번입니다.
3. 비용 산정 기법 ★★★
교재 단원: 소프트웨어 개발 방법론 활용
정보처리기사 필기 (2020.06.06 ~ 2020.09.22) 의 3번의 시험 중 100% 출제된 개념입니다.
소프트웨어를 개발할 때 시간적으로 금전적으로 여러 비용이 발생합니다. 이런 비용들을 개발 계획 수립시에 산정해볼 수 있습니다. 개발에 소요되는 인원, 자원, 기간 등으로 소프트웨어의 규모를 확인하여 개발에 필요한 비용을 산정하는 것입니다. 비용 산정 기법들이 필기 시험에 많이 출제가 되었습니다. (계속 출제되긴 했지만 기출 문제는 너무 지엽적인 것을 많이 물어봐서 기출 보다는 개념들 위주로 학습하는 것이 좋을 것 같습니다)
비용산정 모델은 크게 하향식 산정 방법과 상향식 산정 방법으로 나뉩니다. 전문가를 통해서 위에서 아래 방향으로 (하향식) 하는 방식이 있고, 세부적인 내용을 토대로 산정하는 아래에서 위로 올라가는 (상향식) 방법이 있습니다. 시험에 주로 나오는 방식은 상향식 산정 방법입니다.

비용산정 모델 종류를 구체적으로 보면 다음과 같습니다.
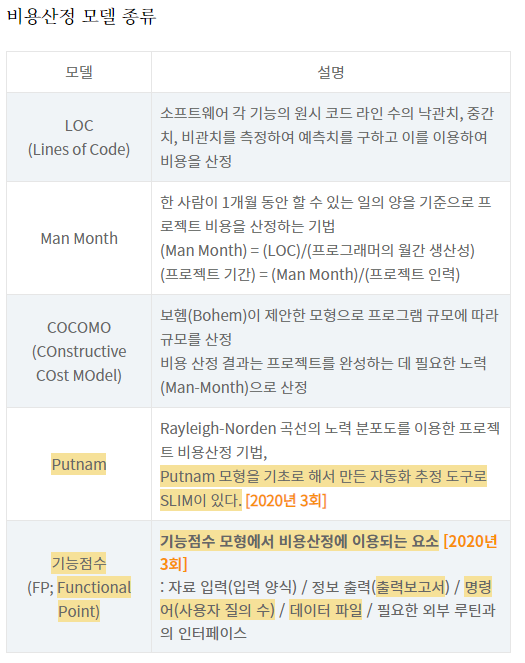
[그림 출처] 위와 동일
Putnam, 기능점수 모형 등에서 굉장히 구체적인 질문들이 나왔습니다. Rayleigh-Norden 곡선의 노력 분포도를 이용한 프로젝트 산정 기법은? => Putnam 이런 식입니다. 여유가 되신다면 위에 표에 정리된 것처럼 구체적인 부분도 다 외우면 좋지만 다 외우지 못한 경우에는 틀려도 괜찮습니다. 그러나 곧 설명드릴 COCOMO와 LOC는 시험에 나오는 부분이 정해져있기 때문에 꼭 외우셔야합니다. (전체 모델들을 구체적으로 공부하고 싶다면? https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=xpiart&logNo=220287976188)
좀 더 일반적인 형태의 문제를 낸다면 다음과 같이 출제됩니다.
91. 소프트웨어 비용 추정모형 (estimation models) 이 아닌 것은?
(1) COCOMO
(2) Putnam
(3) Function-Point
(4) PERT
(2020.09.26 정보처리기사 필기 기출문제 - 출처: 전자문제집 CBT)정답은 위에서 언급되지 않은 4번입니다. COCOMO, Putnam, Function-Point, LOC가 소프트웨어 비용 추정 모형에 해당합니다. 4번 PERT는 프로젝트 일정 계획 만드는 방법입니다.
LOC 문제는 한 번 밖에 출제가 되지 않았지만 앞으로 언젠가 또 나올 문제라 한 번 보고 넘어가는 것이 좋을 것 같습니다. LOC (source Line of Code; 원시 코드 라인수) 는 코드 라인수의 비관치, 낙관치, 기대치를 측정하여 예측치를 구하고, 이걸 기반으로 비용을 산정하는 방법입니다.
LOC 예측치 = { 낙관치 + (4 * 기대치) + 비관치 } / 6
이런 공식을 사용하면 예측되는 총 라인수가 나옵니다. 기대치에 가중치를 많이 주고 낙관치나 비관치에는 많이 주지 않는 공식입니다. 이것보다 시험에 나오는 것은, 이렇게 산정된 라인 수로 개발 기간을 산정하는 것입니다.
개발 기간 = (예측한 총 라인수 / 월 평균 생산성) / 프로그래머 수
입니다. 전체 짜야하는 코드 라인이 있을 때, 한 명이 평균적으로 짤 수 있는 코드를 나누면 혼자 일할 때 몇 달 정도 걸리는지 알 수 있을 것입니다. 그거를 프로젝트에 투입된 인원의 수로 나누면 전체 일의 양을 n 빵하게 되니까 (1/n) 다같이 일을 나눠서 했을 때 걸리는 개발 기간을 알 수 있을 것입니다.
실제 문제를 풀어보면서 어떤 식으로 풀게 되는지 확인해보겠습니다.
94. LOC 기법에 의하여 예측된 총 라인수가 50000라인, 프로그래머의 월 평균 생산성이 200라인, 개발에 참여할 프로그래머가 10인일 때, 개발 소요 기간은?
(1) 25 개월
(2) 50개월
(3) 200 개월
(4) 2000 개월
(2020.06.06 정보처리기사 필기 기출문제 - 출처: 전자문제집 CBT)공식을 엄청 열심히 외우지 않아도 문제에 주어진 숫자들로 계산이 되셨을 것 같습니다. (총 라인수 / 월 평균 생산성) / 프로그래머 수 = (50000 / 200) / 10 = 25 개월인 1번이 답입니다.
4. COCOMO 모델 ★★
교재 단원: 소프트웨어 개발 방법론 활용
정보처리기사 필기 (2020.06.06 ~ 2020.09.22) 의 3번의 시험 중 2번 출제된 개념입니다.
3. 비용산정 모형에서 보았던 방법 중 COCOMO 모델 (Constructive Cost Model) 은 시험에 따로 출제가 많이 되었습니다. 그러나 COCOMO 를 통한 비용 산정보다는 COCOMO 모델에서 구분하는 소프트웨어 개발 유형을 많이 묻게 됩니다. 이 모델에서는 소프트웨어의 복잡도나 원시 프로그램의 규모에 따라 크게 3가지 유형으로 소프트웨어 개발 유형을 구분합니다.
1. Organic Mode (조직형): 기관 내부에서 개발된 중,소규모의 소프트웨어이며 5만 라인 이하 (사무처리용, 업무용)
2. Semi-Detached Mode (반분리형): 조직형과 내장형의 중간형으로 30만 라인 이하 (운영체제, 데이터베이스 관리 시스템 등)
3. Embedded Mode (내장형): 초대형 규모 소프트웨어이며 30만 라인 이상! (미사일 유도 시스템, 실시간 처리 시스템 등)
1에서 3으로 갈수록 5만 라인, 30만 라인, 그 이상으로 점점 커지는 것을 알 수 있습니다. 각 유형의 이름과 이 구분 크기를 외워주시면 됩니다.
문제를 풀어보겠습니다.
89. COCOMO model 중 기관 내부에서 개발된 중소 규모의 소프트웨어로 일괄 자료 처리나 과학기술 계산용, 비즈니스 자료 처리용으로 5만 라인 이하의 소프트웨어를 개발하는 유형은?
(1) embeded
(2) organic
(3) semi-detached
(4) semi-embedded
(2020.06.06 정보처리기사 필기 기출문제 - 출처: 전자문제집 CBT)답은 2번입니다. 5만 라인 이하이므로 organic 이겠죠. 이름과 규모를 잘 매칭하여 외워주시면 됩니다.
5. CMM 모델 ★★
교재 단원: 소프트웨어 개발 방법론 활용
정보처리기사 필기 (2020.06.06 ~ 2020.09.22) 의 3번의 시험 중 2번 출제된 개념입니다.
CMM (Capability Maturity Model; 능력 성숙도 모델) 은 소프트웨어 개발 조직의 업무 능력 및 조직의 성숙도를 평가하는 모델입니다. 앞서 봤던 비용 산정 이런 모델과는 관련이 없고, 특정 회사가 얼마나 개발을 잘하는지 평가하는 한 기준이라고 이해하시면 될 것 같습니다.
CMM 모델에서 성숙도 레벨은 다음과 같이 5가지로 나눕니다. (CMMI 모델과 거의 비슷하고, 약간의 차이가 있습니다. 비교? https://tino1999.tistory.com/10)
1. 초기 단계 (Initial): 그냥 개발 시작하는 단계
2. 반복 단계 (Repeatable): 어느 정도 프로세스가 정립되어서, 그 프로세스대로 반복 가능한 단계
3. 정의 단계 (Defined): 전체 프로세스를 관리하는 절차가 정립된 단계
4. 관리 단계 (Managed): 프로세스 자체가 얼마나 괜찮은지 평가할 수 있는 단계 (잘못된 점 분석 가능)
5. 최적화 단계 (Optimized): 특정 프로세스를 계속 발전시켜서 그 프로세스에 대한 방법이 가장 적절하다고 (최적화가 되었기 때문에) 생각할 수 있는 단계
우리가 사장이 되어서 IT 스타트업을 차렸다면 아무 절차도 정해진 규칙도 없이 일단 개발을 시작하는 1번일 확률이 높을 것입니다. 하지만 점차 시행착오를 거치면서 그 회사만의 프로세스도 생길 것이고 기존 문제들을 보완해서 프로세스가 잘 정립되면 최적화가 된 5번까지 이르게 될 것입니다.
문제를 풀어보겠습니다.
85. CMM (Capability Maturity Model) 모델의 레벨로 옳지 않은 것은?
(1) 최적단계
(2) 관리단계
(3) 정의단계
(4) 계획단계
(2020.06.06 정보처리기사 필기 기출문제 - 출처: 전자문제집 CBT)답은 4번입니다. CMM 모델은 회사의 성숙도를 평가하는 것인데, 계획 단계 같은 회사 단계는 없습니다. 최적화가 되거나, 프로세스의 문제점들을 분석하고 관리하거나, 이제 막 절차가 정의가 되었거나는 할 수 있습니다.
6. 소프트웨어 개발 프레임워크 ★★
교재 단원: 소프트웨어 개발 방법론 활용
정보처리기사 필기 (2020.06.06 ~ 2020.09.22) 의 3번의 시험 중 2번 출제된 개념입니다.
소프트웨어 개발 프레임워크 (Framework) 란 소프트웨어 개발에 공통적으로 사용되는 구성요소와 아키텍처를 일반화하여 손쉽게 구현할 수 있도록 여러 가지 기능들을 제공해주는 반제품 형태의 소프트웨어 시스템입니다. 이름 자체가 Framework 이죠. 간단히 말해서 사람들이 많이 쓰는 거는 미리 만들어서 하나의 틀로 제공해주겠다는 것입니다.
문제에서는 이러한 프레임워크들을 사용했을 때 기대효과를 물어보았습니다.
88. 소프트웨어 개발 프레임워크를 적용할 경우 기대효과로 거리가 먼 것은?
(1) 품질보증
(2) 시스템 복잡도 증가
(3) 개발 용이성
(4) 변경 용이성
(2020.06.06 정보처리기사 필기 기출문제 - 출처: 전자문제집 CBT)답은 2번입니다. 소프트웨어 개발 프레임워크는 자주 쓰이는 것들을 미리 잘 만들어서 제공해주는 것인데 복잡도가 증가하다니 말이 안 되겠죠. 잘 만들어서 제공해주는 것이니 품질 보증도 되고, 개발하기도 쉽습니다. 내가 만든게 아닌데 변경하기가 쉬운가? 하고 헷갈릴 수가 있는데 확실히 아닌 2번이 있어서 답을 찾는 것은 어렵지 않으실 것 같습니다. 프레임워크의 코드들은 기능별로 딱딱 독립적으로 구분이 되어있기 때문에 필요한 것만 수정하고, 사용하고 하기에도 좋습니다.
비슷한 문제를 한 개만 더 풀어보겠습니다.
86. 소프트웨어 개발 프레임워크의 적용 효과로 볼 수 없는 것은?
(1) 공통 컴포넌트 재사용으로 중복 예산 절감
(2) 기술 종속으로 인한 선행 사업자 의존 증대
(3) 표준화된 연계 모듈 활용으로 상호 운용성 향상
(4) 개발 표준에 의한 모듈화로 유지보수 용이
(2020.09.26 정보처리기사 필기 기출문제 - 출처: 전자문제집 CBT)답은 2번입니다. 공통된 것 재사용으로 예산 절감도 맞고, 표준화된 모듈들을 사용해서 기능들 간 연결도 깔끔하게 잘 됩니다. 프레임워크 내부는 보통 모듈화가 되어있어 유지보수하기도 좋습니다. 2번은 맞지 않습니다. 남의 기술에 종속되어 끌려다니는 것이 아니라 필요한 부분을 가져다 쓰는 것입니다.
문제 두 개의 공통점을 보면, 소프트웨어 개발 프레임워크의 특징이 아닌 것을 고를 때는 도덕 문제를 풀 때처럼 부정적인 나쁜 말(?) 을 고르면 됩니다.
7. RIP vs. OSPF ★★
교재 단원: IT 프로젝트 정보시스템 구축관리
정보처리기사 필기 (2020.06.06 ~ 2020.09.22) 의 3번의 시험 중 2번 출제된 개념입니다.
라우팅 프로토콜 (Routing Protocol) 은 라우터 간 통신 방식을 규정하는 통신 규약입니다. 참고로 라우터는 최종 목적지에 가기 위해 한 통신망에서 다른 통신망으로 데이터 패킷을 전송하는 장치입니다. (여러분의 집에 있는 데스크탑에 가기까지 중간에 많은 라우터들을 거치게 됩니다.)

[그림 출처] https://dentuniverse.tistory.com/16
위의 내용은 라우팅 프로토콜이라는 개념이 너무 낯설지 않도록 설명을 드린 것이고, 문제를 풀기 위해 중요한 것은 라우팅 프로토콜의 종류입니다. 이 중 다 못 외우는 경우 RIP와 OSPF를 중점적으로 암기하시면 됩니다.

[그림 출처] https://shlee1990.tistory.com/850
RIP (Routing Information Protocol) 는 가장 먼저 사용된 라우팅 프로토콜입니다. 거리 벡터 알고리즘이라는 알고리즘을 사용합니다. 위에 표에는 언급이 안 되어있는데 최대 홉 (Hop) 수가 15입니다. 홉이 무엇이냐면 위에 보여드렸던 라우터들을 몇 개를 거쳤냐는 뜻입니다. 철수와 영희가 직통으로 연결되어있다면 홉 수는 0이 됩니다. 그러나 중간에 라우터가 있으면 1이 되는 것이죠. 이 홉수가 최대가 15밖에 안 된다는 단점이 있습니다. 홉 수에 제한이 있다니... 현대 사회에 맞지 않겠죠...?
이런 RIP 의 단점을 개선하기 위해 IGRP (Interior Gateway Routing Protocol; 내부 게이트웨이 라우팅 프로토콜) 나 OSPF (Open Shortest Path First) 같은 다른 프로토콜이 등장하였습니다. IGRP는 네트워크의 상태를 고려하여 라우팅하기 때문에 (RIP는 가다가 이상한 경로로 갈 위험이 많았습니다) 경로를 좀 더 잘 찾아갈 수 있었습니다.
OSPF는 전제 OSPF 네트워크를 작은 영역으로 나누어 관리합니다. 그래서 빠르게 업데이트하면서도 효율적인 관리가 가능합니다. 보기에서 나왔을 때 잘 찾으셔야하는 차이점은 RIP는 거리 벡터 알고리즘을 쓰지만 OSPF는 링크 상태 라우팅 프로토콜을 사용합니다. (+ 최단 경로를 찾을 때 사용하는 알고리즘은 다익스트라 알고리즘 방식을 씁니다)
RIP와 OSPF 문제가 나오면 보기에 나온 설명들을 구별할 수 있어야합니다. 다시 정리하면 둘의 가장 큰 차이는 RIP는 15 홉 제한이 있다는 것이고, OSPF는 제한이 없습니다. 또한 RIP는 거리 벡터 라우팅 방식을 쓰지만, OSPF는 링크 상태 라우팅 방식을 씁니다.

[그림 출처] https://ko.gadget-info.com/difference-between-rip
※ BGP는 규모가 큰 네트워크 용입니다.
[참고] 라우팅 프로토콜을 비교하며 이해하기 좋은 그림들
문제를 풀어보겠습니다.
93. RIP (Routing Information Protocol) 에 대한 설명으로 틀린 것은?
(1) 거리 벡터 라우팅 프로토콜이라고도 한다.
(2) 소규모 네트워크 환경에 적합하다.
(3) 최대 홉 카운트를 115홉 이하로 한정하고 있다.
(4) 최단경로탐색에는 Bellman-Ford 알고리즘을 사용한다.
(2020.08.22 정보처리기사 필기 기출문제 - 출처: 전자문제집 CBT)답은 3번입니다. 최대 홉 카운트는 15입니다. 나머지는 RIP에 대한 설명에 해당합니다. 15홉 제한이 있으므로 소규모 네트워크에 적합할 것이고, 최단 경로 탐색 알고리즘은 위에서 보지 않았지만 OSPF가 다익스트라 알고리즘을 사용하기 때문에 이와 대비되는 다른 알고리즘을 쓴다는 것을 알 수 있습니다.
8. 암호화 알고리즘 ★★★
교재 단원: 소프트웨어 개발보안 구축
정보처리기사 필기 (2020.06.06 ~ 2020.09.22) 의 3번의 시험 중 100% 출제된 개념입니다.

암호화 방식에는 양방향과 단방향이 있습니다. 단방향은 Hash 알고리즘을 씁니다. (돈가스를 먹을 때 구석탱이에 같이 주는 해시 포테이토를 아시나요? 감자처럼 정보를 으깨버린다는 뜻입니다.) 단방향이라는 것은 Hash 알고리즘을 통해 암호화시켰을 때 다시 원래 메세지로 돌아올 수 없다는 것입니다.
반대로 양방향 방식은 암호화한 것을 주면 받은 쪽에서 암호화된 거를 풀어서 원래 메세지를 볼 수 있습니다. 이런 양방향 방식에는 개인키 암호화 기법 (Private Key Encryption) 과 공개키 암호화 기법 (Public Key Encryption) 이 있습니다.
개인키 암호화 기법은 동일한 키로 데이터를 암호화도 하고 복호화도 합니다. 개인키 암호화 기법을 분류를 더 쪼개면 (1) 한 번에 하나의 데이터 블록을 암호화하는 블록 암호화 방식 (DES, SEED, AES, ARIA 가 해당합니다!! - 이런 것들이 있구나를 몇 번 봐서 친숙해지셔야합니다. 문제에서 보기로 출제가 되곤 합니다.) 과 (2) 암호화하기 전 평문과 동일한 길이의 스트림을 생성하여 비트 단위로 함호화하는 스트림 암호화 방식 (LFSR, RC4 가 해당합니다) 이 있습니다.
공개키 암호화 기법은 데이터를 암호화할 때 사용하는 공개키 (Public Key)는 데이터베이스 사용자들에게 다 공개하지만, 복호화할 때 사용하는 비밀키 (Secret Key)는 관리자가 비밀리에 관리합니다. 이렇게 다른 키로 복호화와 암호화를 하기 때문에 비대칭 암호 기법이라고도 부릅니다. 대표적으로는 RSA 가 있습니다.
기법들의 차이와 대표적인 예시들을 잠깐 외워보고 문제로 넘어가겠습니다.
87. 큰 숫자를 소인수 분해하기 어렵다는 기반 하에 1978년 MIT에 의해 제안된 공개키 암호화 알고리즘은?
(1) DES
(2) ARIA
(3) SEED
(4) RSA
(2020.08.22 정보처리기사 필기 기출문제 - 출처: 전자문제집 CBT)답은 4번입니다. 공개키 암호화 기법은 공개키와 비밀키를 사용하는 비대칭 암호 기법이고 대표적인 예시는 바로 RSA 입니다. 나머지는 개인키 암호화 기법 중 블록 암호화 방식에 속하는군요.
한번 더 풀어보겠습니다.
92. 공개키 암호화 방식에 대한 설명으로 틀린 것은?
(1) 공개키로 암호화된 메시지는 반드시 공개키로 복호화 해야 한다.
(2) 비대칭 암호기법이라고도 한다.
(3) 대표적인 기법은 RSA 기법이 있다.
(4) 키 분배가 용이하고, 관리해야할 키 개수가 적다.
(2020.09.26 정보처리기사 필기 기출문제 - 출처: 전자문제집 CBT)답은 1번입니다. 비대칭 암호 기법, RSA, 키 개수가 적다 모두 틀린 부분이 보이지 않지만 1번은 확실히 틀린 부분이 보입니다. 공개키로 암호화된 메시지를 비밀키로 복호화하게 됩니다.
9. 정보보안 3대 요소 ★★
교재 단원: 소프트웨어 개발 보안 구축
정보처리기사 필기 (2020.06.06 ~ 2020.09.22) 의 3번의 시험 중 2번 출제된 개념입니다.
정보보안에는 3대 요소가 있습니다. 보안을 위해서는 이 3가지 요소를 균형있게 잘 유지해야합니다.
1. 기밀성 (Confidentiality): 허가를 받은 사람만 정보를 이용할 수 있고, 그 외에 사람은 접근하지 못하게 합니다. (기밀 문서를 아무나 볼 수 없겠죠!)
2. 무결성 (Integrity): 변경은 허락된 사람에게만 (=인가된 사람에게만) 변경 가능합니다. 이렇게 해야 정확한 정보, 완전한 데이터를 유지할 수 있습니다. (무결성은 데이터를 아무나 막 건드리지 않게 해서 결함이 없게 하는 것이죠)
3. 가용성 (Availability): 정보를 필요로 할 때 적절히 사용할 수 있습니다. 원하는 때에 제대로 제공되거나 작동되어야합니다.
※ 참고로 기밀성을 위협하는 공격에는 Snoofing (남의 비밀 정보를 몰래 훔쳐보는 것입니다, Snoofing은 킁킁거리다라는 뜻입니다) 이 있고, 가용성을 위협하는 공격에는 Dos (Denial of Service) 나 DDos (Distributed DoS) 공격이 있습니다. 디도스 공격은 많이 들어보셨을 것 같은데요, 여러 사용자가 동시에 한 서버에 접근이 몰려버리면 접속이 잘 되지 않는 상황이 발생하게 됩니다. 이렇게 하는 공격은 적절할 때에 정보를 사용하는 것을 방해하게 됩니다. (ex. 수강 신청 시기에 사람이 몰려서 페이지가 접속이 잘 안 되는 때를 떠올려 보시면 됩니다.)
문제를 풀어보겠습니다.
82. 정보보안의 3대 요소에 해당하지 않는 것은?
(1) 기밀성
(2) 휘발성
(3) 무결성
(4) 가용성
(2020.08.22 정보처리기사 필기 기출문제 - 출처: 전자문제집 CBT)3대 요소가 아닌 것을 찾기는 쉬우셨을 것 같습니다. 답은 2번입니다.
더 구체적으로 물어보는 문제 예시를 보겠습니다.
100. 시스템 내의 정보는 오직 인가된 사용자만 수정할 수 있는 보안 요소는?
(1) 기밀성
(2) 부인방지
(3) 가용성
(4) 무결성
(2020.06.06 정보처리기사 필기 기출문제 - 출처: 전자문제집 CBT)답은 4번입니다. 기밀성은 허락된 사용자만 접근이 가능하다는 것이고, 가용성은 필요한 때에 정보를 사용하게 하는 것입니다. 인가된 사용자만 내용을 변경할 수 있다는 것은 데이터의 완전성을 유지하는 무결성에 해당합니다.
10. 공격기법 ★★★
교재 단원: 시스템 보안 구축
정보처리기사 필기 (2020.06.06 ~ 2020.09.22) 의 3번의 시험 중 100% 출제된 개념입니다.
공격 기법 문제는 꾸준히 출제가 되지만 외워야할 게 너무 많습니다. 기출 문제를 풀어보면서 눈에 들어오는 몇 가지라도 확실하게 이름과 뜻을 매칭시켜두시면 도움이 될 것입니다. (아래 전체 공격 기법 중 중요한 것들에는 굵게 표시를 해두었습니다)
[참고 1; 아래 그림 출처] https://m.blog.naver.com/wook2124/222108833676
[참고 2] https://1d1cblog.tistory.com/172
(1) 서비스 공격 유형
서비스 공격 유형은 아래와 같이 있습니다. 서버의 자원을 고갈 시키기 위한 DoS 공격, 분산된 공격 지점에서 자원 고갈 공격을 하는 DDos 가 있습니다. (아까 말씀드린 것처럼 동시에 접속자가 몰려서 대학교 수강 신청 사이트가 마비되는 것과 비슷한 느낌입니다.) Ping of Death는 ping 명령 전송을 이용해서 공격 대상의 네트워크를 마비시켜버립니다. smurfing은 IP 특성을 이용해서 이 또한 네트워크를 마비시켜버립니다. SYN Flooding은 과도하게 SYN 패킷을 흘러넘치도록 전송하는 것입니다. Tear drop 은 패킷을 분할하고 정보를 넘겨줄 때 일부러 잘못된 정보를 줘서 조립하는 상대방이 오류로 과부하가 걸리게 하는 것입니다. 눈물방울처럼 조금씩 오류를 내는 것이 누적되면 결국 큰 문제가 생겨 다운되게 됩니다. LAND attack (Local Area Network Denial Attack) 은 자신에게 무한히 응답하도록 하는 공격 방식입니다. 이름 그대로 작은 범위의 네트워크가 자기 자신에게 보내고 자기 자신이 무한히 응답하다가 다운됩니다.
공통점은 무언가를 과도하게 받게 해서 서비스를 다운 시켜버리는 것입니다.

[그림 출처] 위 참조
(2) 네트워크 침해 공격
네트워크 침해 공격은 아래와 같습니다. 스미싱은 많이 들어보셨을 것입니다. 문자를 통해 수상한 링크를 누르게 하는데, 이 링크를 누르면 개인 신용 정보가 빠져나가게 합니다. 스피어 피싱은 다른 공격 기법들이 불특정 다수의 개인정보를 빼내려고 하는 것과 달리 특정인의 정보를 캐내기 위한 방법입니다. 지인인 척 이메일을 보내서 이메일의 첨부파일을 클릭하면 악성코드가 설치되도록 합니다. 지능형 지속 위협은 이름 그대로 특정 대상에 지속적인 공격을 시도하는 것입니다. 그러나 다른 방법들과 달리 목표가 되는 대상 서버를 직접 공격하는 것이 아니라 내부의 PC 를 노리고, 내부 PC를 사용하는 사람을 통해 내부로 침입하는 지능적인 방법을 사용합니다. 무차별 대입 공격은 암호를 알아내기 위해 진짜 그냥 가능한 모든 값을 다 써보는 것입니다. (학교에서 사용하던 번호 자물쇠의 번호를 잊어버리면 모든 조합을 다 돌려본 적이 있으실 겁니다. 이게 무차별 대입 방식입니다.) 큐싱은 QR 코드를 이용해서 금융 정보를 뺏어가는 방식입니다. (스미싱이 SMS, 문자인 것과 비슷하죠) SQL 삽입 공격은 데이터베이스의 SQL 문법을 이용해서 웹사이트의 데이터베이스를 접근하거나 조작할 수 있습니다. (검색창, 파일 업로드 칸 같은 곳에 SQL 문장이 입력되었을 때 처리되지 않도록 홈페이지를 잘 만들어야합니다... 이런 방식으로도 침투할 수 있기 때문입니다.) 크로스 사이트 스크립팅은 악성 스크립트를 이용해서 사용자의 개인 정보를 빼가는 방식입니다. 이것도 SQL 삽입 공격처럼 게시판 같은 입력 창에 악성 스크립트를 썼을 때 실행되어버리면 이곳에 접속한 다른 사용자들은 다 공격에 당하게 됩니다. (그래서 입력창에는 SQL 문장도, 스크립트도 실행되지 않게 잘 막아야합니다...)

(3) 정보보안 침해 공격
정보보안 침해 공격은 다음과 같습니다. 좀비 PC는 악성 코드에 감염되어 좀비처럼 자기 의지를 잃고 조종당하게 되는 것입니다. C&C 서버는 이런 좀비 PC에 명령을 내리기 위한 서버입니다. 봇넷은 악성 프로그램에 감염된 다수의 컴퓨터들이 네트워크로 연결된 형태입니다. 웜은 벌레라는 뜻이죠, 자신을 복제해서 시스템에 점점 부하가 걸리고 결국 시스템은 다운이 됩니다. 제로 데이 공격은 보안 취약점이 발견되었고, 그걸 이제 수정해야하는데 그 전에 그 취약점으로 공격하는 것입니다. (보안 개발자들도 빠르게 문제를 고치고자 할테니 그 전에 공격하려면 공격자 또한 타이밍과 순발력이 중요하겠죠..) 키로거 공격은 사용자의 키보드 움직임을 다 로깅해두었다가 (저장해두었다가) 비밀번호 같은 키보드 입력 값들을 몰래 빼가는 것입니다. 랜섬웨어는 요즘 정말 많이 들어보셨을 것 같습니다. 내부 파일을 다 암호를 걸어버리고 비트코인을 주면 파일을 풀어주겠다고 공격하는 방법이죠. 백도어는 해커들이 한번 침투한 시스템에 다음번에도 침투하기 위해 뒷문을 만들어두는 것입니다. 트로이 목마는 그리스 로마 신화에 나오는 군사들을 몰래 숨겨둔 트로이 목마와 같습니다. 겉으로는 정상적인 프로그램처럼 보이지만, 그 내부에는 악성코드가 숨어 있습니다.

문제를 풀어보겠습니다.
94. 웹페이지에 악의적인 스크립트를 포함시켜 사용자 측에서 실행되게 유도함으로써, 정보유출 등의 공격을 유발할 수 있는 취약점은?
(1) Ransomware
(2) Pharming
(3) Phishing
(4) XSS
(2020.09.26 정보처리기사 필기 기출문제 - 출처: 전자문제집 CBT)답은 4번입니다. 이런 식으로 어떤 공격인지 설명이 나왔을 때 이름을 맞출 수 있으면 됩니다.
보너스. CBD ★
교재 단원: 소프트웨어 개발 방법론 활용
정보처리기사 필기 (2020.06.06 ~ 2020.09.22) 의 3번의 시험 중 1번 출제된 개념입니다.
CBD (Component Based Design; 컴포넌트 기반) 방법론은 소프트웨어 개발 방법론 중 하나입니다. 이름대로 컴포넌트 기반으로 개발하는 것입니다. 기존의 시스템이나 소프트웨어를 구성하는 컴포넌트들을 조합하여 하나의 새로운 애플리케이션을 만들게 됩니다.
컴포넌트 기반으로 개발하게 되면 여러 장점들이 있습니다. 컴포넌트의 재사용이 가능하기 때문에 새로 만들지 않아도 되어서 시간과 노력을 절감할 수가 있습니다. 컴포넌트들로 나뉘어져 있으므로 유지보수도 쉬워서 유지보수 비용도 최소화활 수 있습니다. 생산성과 품질도 좋아집니다.
컴포넌트 기반 방법론의 절차는 개발 준비 단계 -> 분석 단계 -> 설계 단계 -> 구현 단계 -> 테스트 단계 -> 전개 단계 -> 인도 단계 로 이루어집니다.
문제를 풀어보겠습니다.
95. CBD (Component Based Development) 에 대한 설명으로 틀린 것은?
(1) 개발 기간 단축으로 인한 생산성 향상
(2) 새로운 기능 추가가 쉬운 확장성
(3) 소프트웨어 재사용이 가능
(4) 1960년대까지 가장 많이 적용되었던 소프트웨어 개발 방법
(2020.09.26 정보처리기사 필기 기출문제 - 출처: 전자문제집 CBT)나머지는 CBD의 장점들에 해당하는 것이 맞습니다. 답은 4번입니다. 1960년대라니 컴포넌트 기반 방식은 요즘 방식일 텐데, 너무 먼 시기입니다. 정확히 풀이하면 1960년대는 소프트웨어 개발 방법론이 없어 무원칙의 상향식 프로그래밍 방식으로 개발하던 시기입니다. (참고: https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=kej_0209&logNo=221308592893)
보너스. 신기술 용어 ★★★
교재 단원: IT 프로젝트 정보시스템 구축관리
정보처리기사 필기 (2020.06.06 ~ 2020.09.22) 의 3번의 시험 중 100% 출제된 개념입니다.
외워야하는 양에 비해 제일 효율이 안 나오는 것이 신기술 동향 공부이지 않을까 싶습니다. 그래서 보너스 개념으로 뺐습니다. 다른 개념들을 학습하신 후에 마지막으로 가능하다면 아래 몇 가지를 더 암기하는 것을 추천드립니다.
[아래 정리된 표 출처] https://blog.naver.com/PostView.naver?blogId=wook2124&logNo=222108831385&parentCategoryNo=&categoryNo=117&viewDate=&isShowPopularPosts=false&from=postView
(1) 네트워크 관련 신기술
이 중 중요한 것을 꼽자면 사물 간 통신이 되는 (인공지능 스피커와 세탁기 연결 등...) IoT, 대규모 디바이스 네트워크 기술인 Mesh Network, 근거리 무선 통신 NFC, 독립된 통신 장치가 블루투스 기술 등을 이용하여 무선 통신망을 형성하는 PICONET, 재난 현장과 같은 장소에 구축하는 Ad-hoc Network 이 될 것 같습니다.
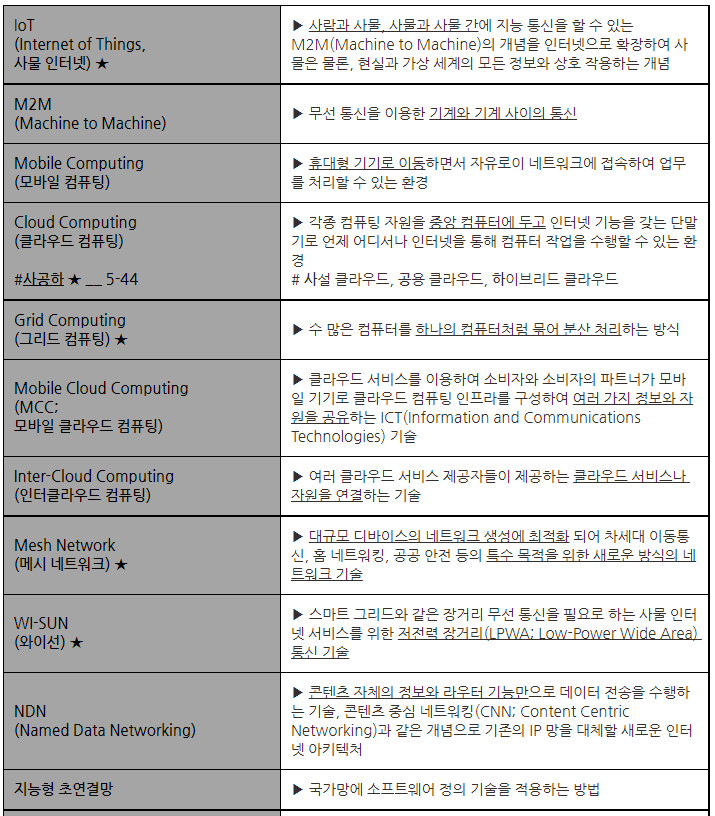

기출 문제를 풀어보겠습니다.
90. 기존 무선 랜의 한계 극복을 위해 등장하였으며, 대규모 디바이스의 네트워크 생성에 최적화되어 차세대 이동통신, 홈네트워킹, 공공 안전 등의 특수목적을 위한 새로운 방식의 네트워크 기술을 의미하는 것은?
(1) Software Defined Perimeter
(2) Virtual Private Network
(3) Local Area Network
(4) Mesh Network
(2020.08.22 정보처리기사 필기 기출문제 - 출처: 전자문제집 CBT)신기술 용어와 간단한 설명을 잘 학습하셨나요? 답은 4번입니다.
(2) 소프트웨어 관련 신기술
이 중에서도 중요한 것을 꼽자면 역시 인간과 같이 지능을 가진 시스템인 인공지능 (AI), 인간의 두뇌를 모델로 만든 기계 학습 기술인 딥러닝, 온라인 금융 거래 정보를 참여자들이 분산 저장하는 (블록들을 체인 형태로 연결해서 저장합니다) 블록 체인, 악성프로그램과 달리 설치시 사용자의 동의를 받아 설치하는 그레이웨어, 웹에서 제공하는 콘텐츠들을 조합하여 새로운 서비스를 만드는 매시업, 현실 속의 사물을 소프트웨어로 가상화하여 모의 실험 등에 사용하는 디지털 트윈이 있을 것입니다.



기출 문제를 풀어보겠습니다.
83. 다음 빈칸에 알맞은 기술은?
( )은/는 웹에서 제공하는 정보 및 서비스를 이용하여 새로운 소프트웨어나 서비스, 데이터베이스 등을 만드는 기술이다.
(1) Quantum Key Distribution
(2) Digital Rights Management
(3) Grayware
(4) Mashup
(2020.08.22 정보처리기사 필기 기출문제 - 출처: 전자문제집 CBT)답은 바로 4번입니다!
(3) 하드웨어 관련 신기술
이 중에서 중요한 개념을 선택해보면 서로 다른 단말기에서 동일한 콘텐츠를 자유롭게 이용할 수 있는 (넷플릭스를 핸드폰으로도 보고 TV로도 보고...) N-Screen 이 있습니다.


N-Screen 이 보기로는 많이 나왔지만 아직 문제에서 묻는 답으로는 나오지 않았네요.
(4) 데이터베이스 관련 신기술
이 중에서 중요한 걸 꼽자면 막대한 양의 데이터 집합인 빅데이터, 오픈 소스 기반으로 분산 컴퓨팅을 하고 가상화된 대형 스토리지를 형성하는 하둡, 대용량 데이터를 분산 처리하고 중복 데이터를 제거하는 맵 리듀스, 대량의 데이터 속에 내재된 패턴을 찾아내는 데이터 마이닝이 있습니다.

기출문제를 풀면 다음과 같습니다.
99. 다음 내용에 적합한 용어는?
- 대용량 데이터를 분산 처리하기 위한 목적으로 개발된 프로그래밍 모델이다.
- Google에 의해 고안된 기술로써 대표적인 대용량 데이터 처리를 위한 병렬 처리 기법을 제공한다.
- 임의의 순서로 정렬된 데이터를 분산 처리하고 이를 다시 합치는 과정을 거친다.
(1) MapReduce
(2) SQL
(3) Hijacking
(4) Logs
(2020.09.26 정보처리기사 필기 기출문제 - 출처: 전자문제집 CBT)답은 맵리듀스, 1번입니다.
참고
정보처리기사 필기 전자문제집 CBT: https://www.comcbt.com/xe/iz
반응형'시험 요점정리 (꽃길) > 정보처리기사' 카테고리의 다른 글
정보처리기사 실기 - 출제 예상 개념 전체 요점 정리 (기출문제) (0) 2021.08.10 정보처리기사 실기 목차 (0) 2021.08.10 정보처리기사 필기 4과목 - 프로그래밍 언어 활용 (빈출 요점 정리) (16) 2021.07.29 정보처리기사 필기 3과목 - 데이터베이스 구축 (빈출 요점 정리) (5) 2021.07.27 정보처리기사 필기 2과목 - 소프트웨어 개발 (빈출 요점 정리) (6) 2021.07.21
